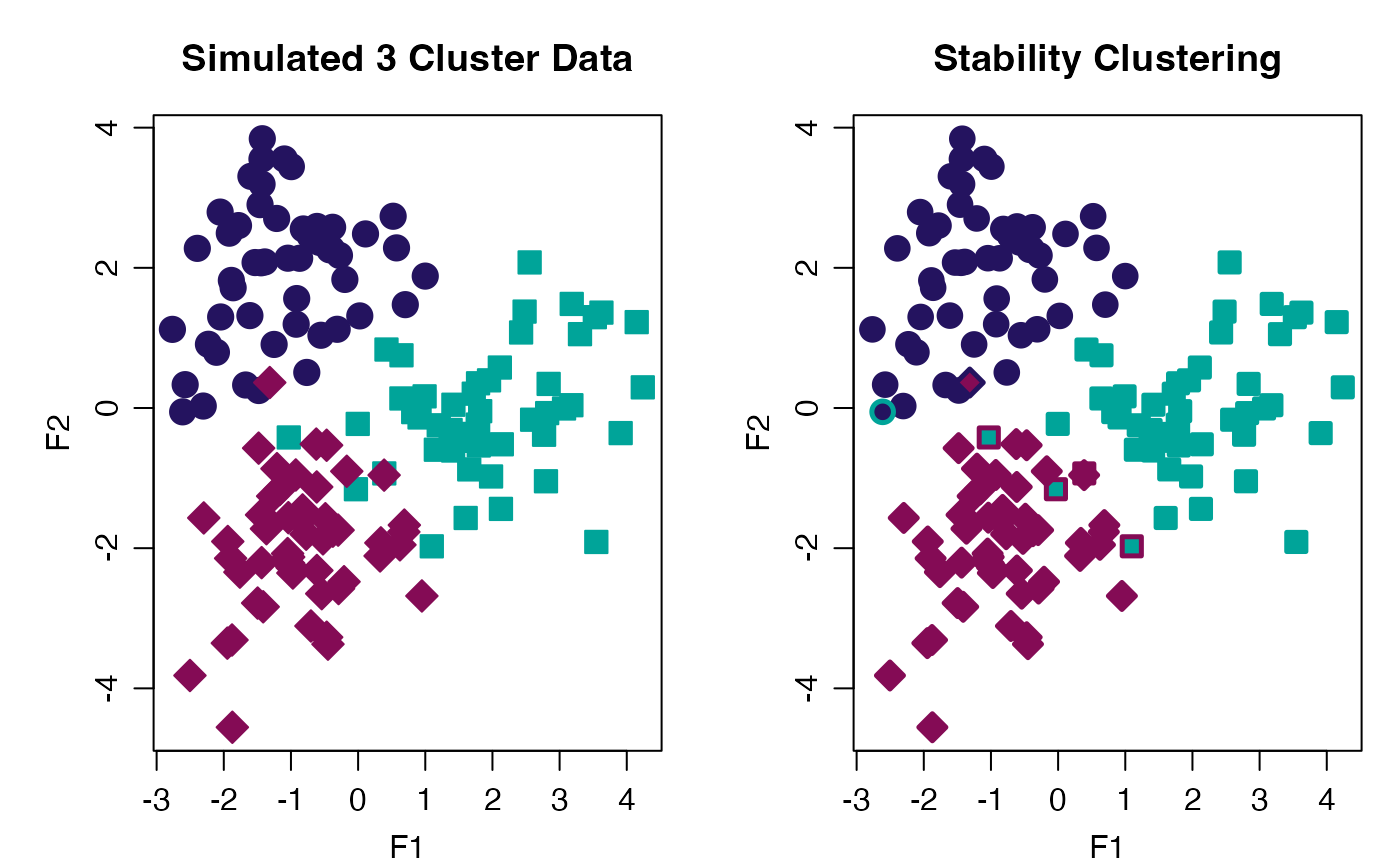Perform Stability Clustering
stability_cluster.RdPartitioning Around Medoids (PAM) is used both because it uses
a more robust measurement of the cluster centers (medoids) and
because this implementation keeps the cluster labels consistent
across runs, a key feature in calculating the across run
stability. This does not occur using kmeans() where the
initial cluster labels are arbitrarily assigned.
Arguments
- data
A \(n \times p\) data matrix containing n samples and p features. Can also be a data frame where each row corresponds to a sample or observation, and each column corresponds to a feature or variable.
- k
integer(1). The number of clusters.- n_iter
integer(1). Defining the number of sub-sampling iterations during each selection.- r_seed
integer(1). Seed for the random number generator, for reproducibility.
Value
A \(n \times (k + 1)\) dimensional tibble of clustering
probabilities for each k, plus a final column
named prob_k, which indicates the "most probable"
cluster membership for that sample.
Note
How do we make sure clusters are indexed the same as what comes out of k-means? Could be susceptible to index errors (but seems ok for now).
See also
Other cluster:
progeny_cluster()
Examples
stab_clust <- stability_cluster(progeny_data, k = 3L,
n_iter = 750L, r_seed = 999) |>
dplyr::mutate(true_cluster = rep(1:3L, each = 50L))
# View stable clusters
stab_clust
#> # A tibble: 150 × 5
#> `k=1` `k=2` `k=3` prob_k true_cluster
#> <dbl> <dbl> <dbl> <int> <int>
#> 1 0.675 0.165 0.16 1 1
#> 2 0.668 0.161 0.171 1 1
#> 3 0.661 0.172 0.167 1 1
#> 4 0.671 0.145 0.184 1 1
#> 5 0.671 0.155 0.175 1 1
#> 6 0.669 0.144 0.187 1 1
#> 7 0.689 0.153 0.157 1 1
#> 8 0.656 0.16 0.184 1 1
#> 9 0.644 0.172 0.184 1 1
#> 10 0.675 0.153 0.172 1 1
#> # ℹ 140 more rows
# confusion matrix
stab_clust |>
with(table(truth = true_cluster, predicted = prob_k))
#> predicted
#> truth 1 2 3
#> 1 49 1 0
#> 2 0 46 4
#> 3 1 1 48
# View the incorrectly clustered samples
stab_clust |>
filter(prob_k != true_cluster)
#> # A tibble: 7 × 5
#> `k=1` `k=2` `k=3` prob_k true_cluster
#> <dbl> <dbl> <dbl> <int> <int>
#> 1 0.388 0.427 0.185 2 1
#> 2 0.175 0.353 0.472 3 2
#> 3 0.171 0.393 0.436 3 2
#> 4 0.188 0.403 0.409 3 2
#> 5 0.169 0.359 0.472 3 2
#> 6 0.197 0.419 0.384 2 3
#> 7 0.66 0.179 0.161 1 3
# Plot Stability Clusters
cols <- c("#24135F", "#00A499", "#840B55")
withr::with_par(list(mgp = c(2.00, 0.75, 0.0),
mar = c(3, 4, 3, 1), mfrow = 1:2L), {
plot(progeny_data,
col = cols[stab_clust$true_cluster],
bg = cols[stab_clust$true_cluster],
pch = stab_clust$true_cluster + 20,
lwd = 1, cex = 1.75,
main = "Orig. Simulated 3 Cluster Data")
plot(progeny_data,
col = cols[stab_clust$prob_k],
bg = cols[stab_clust$true_cluster],
pch = stab_clust$true_cluster + 20,
lwd = 2.5, cex = 1.5,
main = "Predicted Clusters via Stability Clustering")
})